Hypothesis Testing
This read will cover what hypothesis testing is, and when and how to use it in your data science project…
Contents
- What is hypothesis testing
- Performing hypothesis testing in machine learning
- Steps in hypothesis testing
- Possible errors while performing hypothesis testing
1. What is hypothesis testing
Any data science project starts with exploring a set of sample data through exploratory data analysis and inferal statistics. Then we want to use these observations to draw inferences about the entire population.
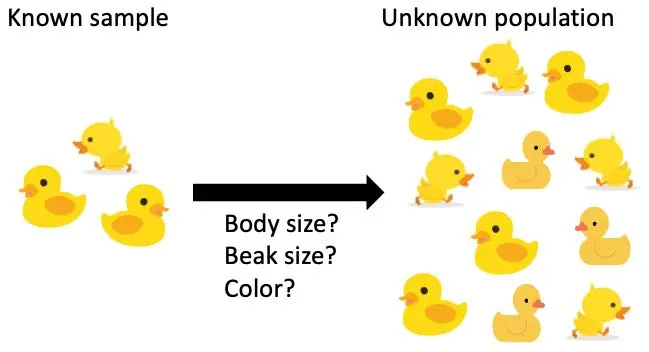
Figure 1: Using samples to make inferences about the population
{kind=link}
Hypothesis testing is used to determine if in the known sample, we have enough statistical evidence to draw conclusions about the population, within a desied error limit.
2. Performing hypothesis testing in your machine learning
Hypothesis testing comes after data pre-processing and model building steps. We use hypothesis testing to build confidence in the machine learning model by making sure the model makes significantly correct predictions of the population.
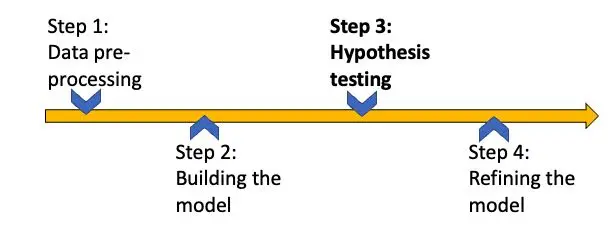
Figure 2: Steps in any ML project and when to perform hypothesis testing
For instance, let’s take a linear regression model where we formulate the intercept and the beta coefficients. Everytime we build the model, we check if the model is significant by performing hypothesis testing on the parameters to make sure they are significant.
3. Steps in hypothesis testing
1) Formulate the hypothesis There are two hypothesis that should be formulated.
Null hypothesis: $H_0:$ The initial claim based on the sample. Eg: The model is not significant. Alternative hypothesis: $H_1:$ This is the counter argument to $H_1$. Usually we want to prove this is true.
2) Determine the significance level
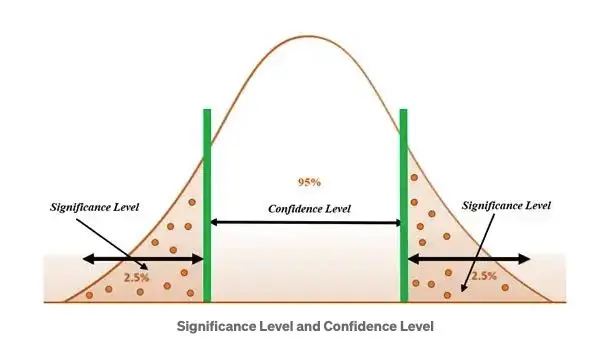
Figure 3: Critical region and confidence interval
Significant level refers to the proportion of the sample laying in the rejection region and the confidence level refers to the proportion laying in the acceptance region. In Figure 3, the significane level is 5% i.e., $\alpha$=5%.
If P-value $\leq$ $\alpha$ ; Reject $H_0$ If P-value $>$ $\alpha$ ; Fail to reject $H_0$
3) Determine the type of the test
| Dataset attributes | Type of the predictor variable | Predictor variable distribution | Desired test |
|---|---|---|---|
| Sample size $\geq$ 30, $\sigma$ known | Quantitative | Normal dist. | Z-test |
| Sample size $<$ 30, $\sigma$ unknown | Quantitative | T dist./ Normal dist. | T-test |
| Compare 3 or more variables | Quantitative | Positively skewed | F-test |
| Test for independance, goodness of fit , test for homogeneity | Categorical | NA | Chi-squared test |
4) Calculate test statistic values and P-values

Figure 4: Test statistics of Z-test, T-test, F-test, and chi-squared test
When we need to compare the means of two samples, we can use two sample tests.
5) Decision making Next we find the P-value associated with the test statistic. P-value is a measure of how strong the evidence is in favour of the null hypothesis. If the P-value $\leq$ $\alpha$ there is enough evidence to reject $H_0$ and if the P-value $>$ 0, there is no sufficient evidence to reject $H_0$.
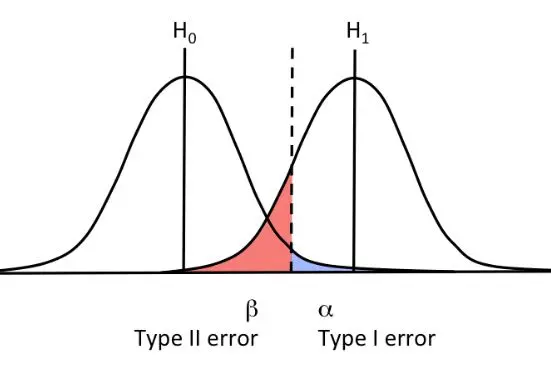
4. Possible errors while performing hypothesis testing

Figure 5: Possible errors in hypothesis testing: type I error and type II error
Type I error: Happens when the null hypothesis is true but we reject it. The level of significance: $\alpha$ is the probability of type I error.
Type II error: Happens when the null hypothesis is false but we fail to reject it. The probability of type II error is commonly denoted (in Figure 6) as $\beta$.