In this post, we will go through what sampling is and the different methods to choose for different problems.
Some of the sampling methods we cover in this post are:
- Random Sampling
- Stratified Sampling
- Cluster Sampling
- Convenience Sampling
- Systematic Sampling
- Gibb’s Sampling
- Random Sampling:
Simple random sampling is a technique to sample a small segment of the population from a whole population. In terms of data, sample random data points from the whole data set.
So what exactly does the random sample do? well, the probability of selecting a random data point from the whole data set is equal to every other data point. so, there is no kind of bias imposed on sampling data from the population.
# you can achieve similar thing in python by:
import random
a = [1, 2, 3, 4, 5]
random.sample(a,2)
>> [1, 3]
# for pandas dataframe
import pandas as pd
import numpy as np
population = pd.DataFrame(np.array([[1,2,3],[4,5,6],[7,8,9]]))
population.sample(n = 1)
>> 0 1 2
>> 2 7 8 9
# returns 2nd row which is [7, 8, 9]
- Stratified Sampling:
If you have chosen Random sampling to sample from a population, let’s say men and women, but every time you sample, you are getting men for most of the time, at least out of 10 random samples from a population of 100, 9 of them are men. even if you have the same probability of sampling outcomes, there’s a chance that you get this kind of output.
But the scope/objective is to sample random but from a subclass having an equal sample population. (say class 0 is men and class 1 is women- 2 subclasses).
This is where stratified sampling is necessary, in terms of data set, suppose you have a classification problem but you need an almost equal number of samples from both the classes in a batch of data so you don’t bias your learning step. Random stratified sampling samples the same number of data points from different classes in the dataset.
Another scenario of data sets to have stratified sampling is, let’s say you have class imbalanced dataset, you wanted to split the dataset to have proportionate classes into train and validation sets. Stratified ensures that relative class frequencies are approximately preserved in each train and validation fold.
click here and Jump to section 3.1.2.2 for more implimentation details in sklearn
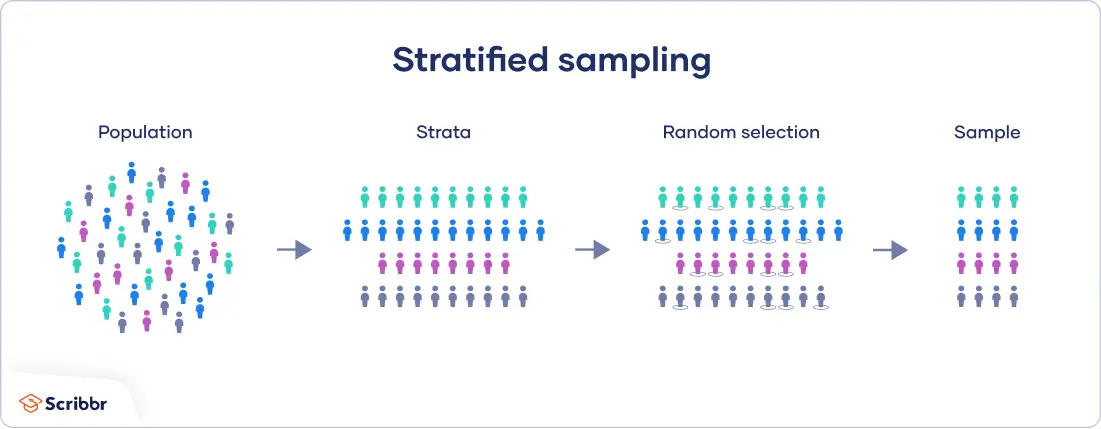 >
Image credits
>
Image credits - Cluster Sampling
Cluster sampling is somewhat the same as stratified sampling. cluster sampling is a probability sampling method in which you segregate the population into respective clusters and randomly select some of the samples from the clusters. The clusters are basically each be a mini representation of the population as a whole.
Let’s say you wanted to get all the board scores of medical students in the US. for this task you need to go to every other school and record the scores or collect them electronically in a database. Instead, break them into clusters. As the entire cluster is representative of the population as a whole. i.e consider schools from texas as a cluster, in general students in medical school are intelligent and probably have the same male-to-female ratio. In this aspect, they represent all the medical schools as a whole.
Texas is a chosen cluster, now randomly pick a cluster let’s say Boston medical school, and evaluate with chosen cluster(texas). randomly selecting and sampling from the clusters allows you to imitate simple random sampling, which in turn supports the validity of your results.
If the clusters are not representative, then random sampling will allow you to gather data on a diverse array of clusters, which should still provide you with an overview of the population as a whole. Reference
- Convenience Sampling.
It is one of the non-probability samplings where you select the sample from the population that is close to hand(which describes the name convenience). For instance, in a magic show asking people to volunteer. In this example, the criteria is nothing but people are available and willing to contribute/participate. This type of sampling method does not require that a simple random sample is generated since the only criterion is whether the participants agree to participate.
This is not recommended in reality because it doesn’t provide any representation of the population. But it can be handy in some situations. for example, a college student wants to record how many hours an average student studies on the night of an examination, in this case, he can call a bunch of his friends and record the hours, or go to a library and do a short survey. The collected samples may not be a representation of the population of interest and therefore be a source of bias.
On contrary, from the same example above, if the town has most of the people as college students and the student makes surveys in the available libraries, this may have a fair chance to be a representation of the population. i.e larger sample size will reduce the chance of sampling error occurring.
- Systematic Sampling
Systematic sampling is a probability sampling method, where we select every Kth element/sample on a list of population. Observe that if the population is random, this can be viewed as simple random sampling. The most commonly used type of systematic sampling is the equiprobability method. In this method, the population list is treated as circular, and every Kth element is sampled.
With that being said, it can be represented as K = N/n where n: sample size, N: population size
This is similar to simple random sampling because each sample chosen from the population has an equal probability of selection. However it is not true in all cases, for example, samples with at least two samples adjacent to each other will never be chosen by systematic sampling, i.e not every possible sample of a particular size has an equal probability of being chosen.
systematic sampling On a dataframe
def systematic_sampling(df, step):
# df - pandas dataframe
# step - value of k (every kth sample to be chosen)
indexes = np.arange(0, len(df), step=step)
systematic_sample = df.iloc[indexes]
return systematic_sample
- Gibb’s Sampling
This is only significant if you are sampling from a multivariate distribution. Until now we have seen a single dimension distribution sampling. Gibb’s sampling is useful for 2 or more dimensional distributions.
When do we use Gibb’s sampling:
- When sampling from a joint distribution P(X, Y) is difficult. i.e getting a pair of x and y is difficult.
- It is easier to sample from a conditional distribution i.e P(X/Y).
Assume p(x/y) is a normal distribution, this means if you have a fixed value y and you need to sample x, you need a single variable normal distribution with provided mean and standard deviation/variance.
Steps:
- We start by initializing some (Xo, Yo) from the population.
- From the first sample keep the Yo fixed, and sample the new X1 from the conditional distribution X1 ~ P(X1/Yo). i.e sample the new value is X from the given existing value of Y.
- Now, from step 2, we sample the new value for Y1, provided the existing value of updated X(form step2) from the conditional distribution Y1 ~ P(Y1/X1)
Repeat steps 2,3 as many times as you need for the number of samples.
Some of the problems from Gibb’s sampling:
|
v
y-axis
>> 1 0 0.5
>> 0 0.5 0
>> 0 1 <- x-axis
From the above examples, consider 0, 0.5 are the probabilities for you to move/shift/sample the data and you are at position (0,0), if you want to sample any of the X, Y directions, you have a low probability of choosing a sample(since you can only choose X or Y from the steps 2 and 3), hence you stay at the same position, therefore you’ll never get a chance to sample from (1,1).
This is also applicable to the high density/probability case. since you’ll not have 2 dimensions all the time, the sampling may also get stuck at high density/probability areas, and never sample from low probability samples. Although Gibb’s sampling is efficient this make Gibb’s sampling a very long time to converge.
-Siddhartha Putti
putti.s@northeastern.edu