| Name | |
|---|---|
| Ashkan Ghanavati | ghanavati.ash@northeastern.edu |
| Bardia Mouhebat | mohebat.b@northeastern.edu |
| Komal Pardeshi | pardeshi.k@northeastern.edu |
| Moheth Muralidharan | muralidharan.mo@northeastern.edu |
| Thomas George Thomas | thomas.th@northeastern.edu |
Outline
1. Introduction
1.1. Problem Statement
In today’s data-driven world, businesses are constantly seeking ways to better understand their customers, anticipate their needs, and tailor their products and services accordingly. One powerful technique that has emerged as a cornerstone of customer-centric strategies is “Customer segmentation”: the process of dividing a diverse customer base into distinct groups based on shared characteristics, that allows organizations to effectively target their marketing efforts, personalize customer experiences, and optimize resource allocation.
1.2. Methodology
Clustering, being a fundamental method within the field of unsupervised machine learning, plays a pivotal role in the process of customer segmentation by leveraging the richness of customer data, including behaviors, preferences, purchase history, beyond the geographic demographics to recognize hidden patterns and subsequently group customers who exhibit similar traits or tendencies. As population demographics are proven to strongly follow the Gaussian distribution, a characteristic tendency in an individual could be possessed by other individuals in the relevant cluster, which then may serve as the foundation for tailored marketing campaigns, product recommendations, and service enhancements. By understanding the unique needs and behaviors of each segment, companies can deliver highly personalized experiences, ultimately fostering customer loyalty and driving revenue growth.
In this project of clustering for customer segmentation, we will delve into the essential exploratory data analysis techniques, unsupervised learning methods such as K-means clustering, followed by Cluster Analysis to create targeted profiles for customers.
1.3. Goals
The goals of this project comprised of the following:
- Test-Driven Development (TDD)
- Orchestrating the data pipeline in Airflow and Docker
- Versioning the transformed data using DVC
- ML model training using Vertex AI in Google Cloud Platform (GCP)
- Versioning the models and Hyperparameter tuning using MLflow
- Serving the Model using Flask API on GCP
- Monitoring data and concept drifts (if any) using the monitoring dashboard on Looker
- Maintaining CI/CD Process using Pytest through GitHub actions
Thus, this project shall serve as a simulation for real-world application in the latest competitive business landscape. We aim to further apply these clustering algorithms to gain insights into customer behavior, and create a recommendation system as a future scope for lasting impact on customer satisfaction and business success.
The source code for our project can be found here: GitHub
1.4. Tools Used for MLOps
- Python >=3.8
- GitHub Actions
- Docker
- Airflow
- DVC
- MLflow
- TensorFlow
- Flask
- Google Cloud Platform (GCP)
- VertexAI
- GCS
- Artifact Registry
- BigQuery
- Looker
1.5. Project Architecture
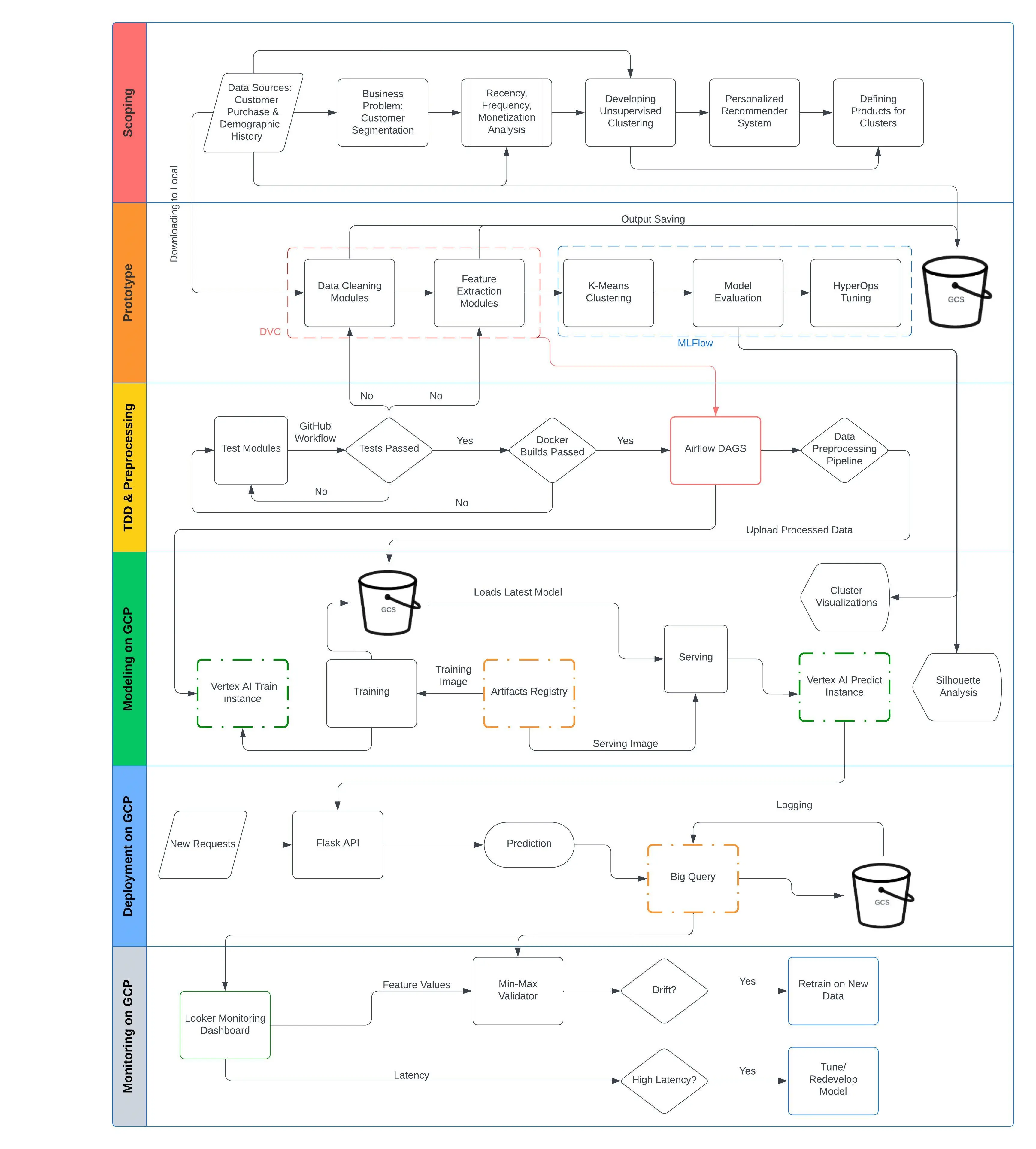
The Project pipeline comprises of data pipeline preparation, ML model training, ML model update, exploring the extent of data and concept drifts (if any) through monitoring, and CI/CD Process demonstration. The details of each stage is described in detail in the following pages.