Table of Contents
Dataset Information
The dataset we will work with consists of reviews and metadata for video games and toys sourced from a comprehensive collection of Amazon product reviews. This dataset serves a crucial purpose for our eCommerce chatbot project by providing valuable insights into customer experiences, preferences, and sentiments regarding our products. Analyzing this data can enhance the chatbot’s ability to respond to user inquiries with relevant and context-specific information.
The relevance of this dataset lies in its ability to inform our understanding of customer opinions and trends within the video game and toy markets. We can create a more dynamic and interactive shopping experience by leveraging the review and metadata components. The reviews provide qualitative insights, while the metadata offers essential product details such as categories, ratings, and pricing information, which are integral to answering user queries accurately.
Using this dataset will also enable us to implement a more intelligent retrieval system that enhances the user experience by allowing personalized interactions based on past customer feedback and product attributes. This dual approach will increase customer satisfaction and help drive sales by providing users with the information they need to make informed purchasing decisions.
Link to the Dataset UCSD - Amazon Product Reviews.
1. Data Card
This project utilizes two types of datasets:
User Reviews Dataset
| Feature Name | Feature Data Type | Feature Description |
|---|---|---|
rating |
Float | Rating of the product |
title |
String | Title of the user review |
text |
String | Text body of the user review |
images |
List | Images posted by user after they receive the product |
asin |
String | ID of the product |
parent_asin |
String | Parent ID of the product |
user_id |
String | ID of the reviewer |
timestamp |
Integer | Time of the review |
verified_purchase |
Boolean | User purchase verification |
helpful_vote |
Integer | Helpful votes of the review |
Product Metadata Dataset
| Feature Name | Feature Data Type | Feature Description |
|---|---|---|
main_category |
String | Domain of the product |
title |
String | Name of the product |
average_rating |
Float | Rating of the product shown on the product page |
rating_number |
Integer | Number of ratings for the product |
features |
List | Bullet-point format features of the product |
description |
List | Description of the product |
price |
Float | Price in US dollars |
images |
List | Images of the product |
videos |
List | Videos of the product, including title and URL |
store |
String | Store name of the product |
categories |
List | Hierarchical categories of the product |
details |
Dictionary | Product details, including materials, brand, sizes, etc. |
parent_asin |
String | Parent ID of the product |
bought_together |
List | Recommended bundles from the website |
1.1. Video Games Dataset:
The user reviews dataset is stored in the file Video_Games.jsonl, containing 4,624,615 records across 10 columns. It occupies approximately 3.5 GB of memory and includes 53,646 duplicate entries, but no missing values. Notably, 61% of the products have received a 5-star rating, and 10% of the titles include the phrase “five stars,” offering valuable insights into customer preferences and product ratings in the video game sector.
The metadata for this category is contained in the file meta_Video_Games.jsonl, which includes 137,269 records across 16 columns. This file occupies 596.4 MB of memory and has no duplicate entries. However, several columns, such as “features,” “description,” and “price,” have missing data, with 29%, 38%, and 55% of their values missing, respectively. While only 1% of products lack images, 79% have missing video links. The metadata provides key product details, with 59% of products categorized under “Video Games” and 8% receiving a 5-star rating.
1.2. Toys and Games Dataset:
The user reviews dataset for this category is stored in the file Toys_and_Games.jsonl, containing 16,260,406 records across 10 columns. The dataset occupies 2.9 GB of memory and includes 53,646 duplicate entries but no missing values. Among the products, 67% have received a 5-star rating, while 9% of purchases were not verified. Additionally, 78% of products have no helpful votes, providing a comprehensive resource for analyzing user behavior and review patterns in the toys and games sector.
The metadata for toys and games products is stored in the file meta_Toys_and_Games.jsonl, which contains 890,874 records across 16 columns. This dataset occupies 3.7 GB of memory and has no duplicate entries. Missing data is observed in 20% of the “features” column, 52% of the “price” column, and 65% of the video links. Furthermore, 10% of the “categories” column entries are incomplete. The majority of products (80%) fall under the “Toys and Games” category, and 13% have a 5-star rating. This metadata offers valuable insights into product characteristics and consumer preferences in this domain.
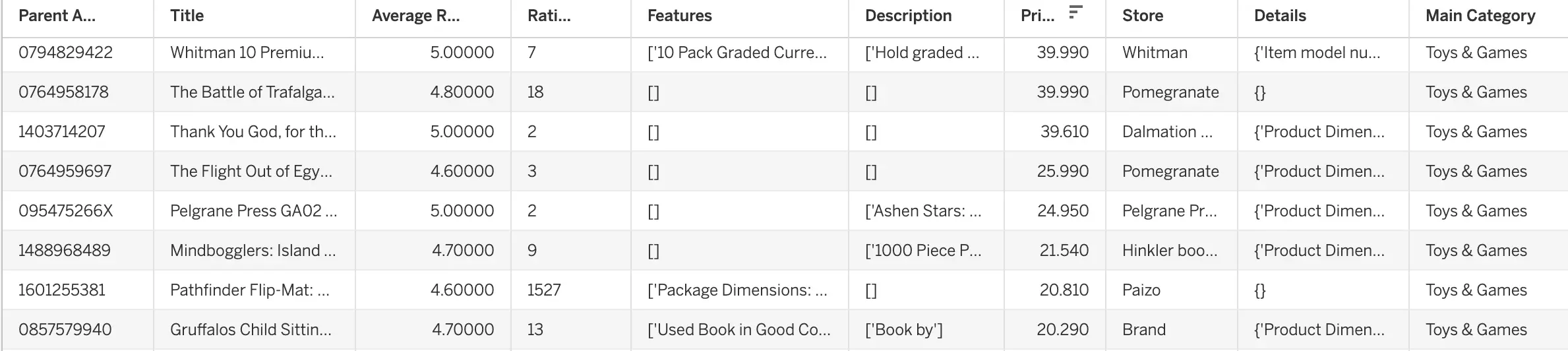
Sample of the cleaned product metadata dataset,
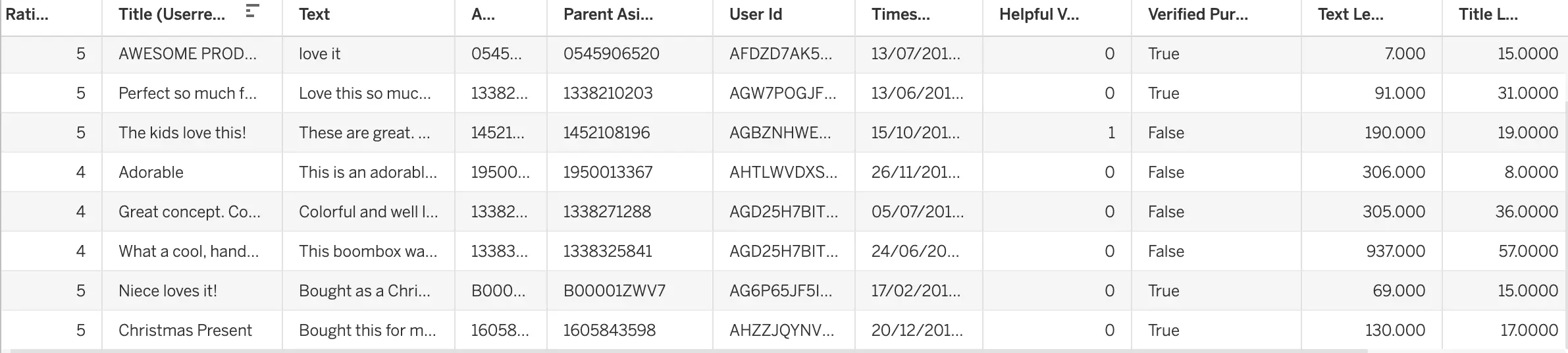
Sample of the user reviews dataset,
2. Data Rights and Privacy
The dataset utilized in this project is governed by the MIT License, which provides flexibility in terms of usage, modification, and distribution with minimal restrictions. However, as part of our research, it is crucial to address data rights and privacy, particularly given the user-generated content involved, such as reviews and identifiers like user_id and timestamp. While the MIT License grants broad permissions, we have taken steps to ensure compliance with data protection regulations, including the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). This involves anonymizing or pseudonymizing personally identifiable information (PII) to safeguard users’ privacy and mitigate the risk of sensitive data being misused. Additionally, we have ensured that the data handling practices align with the relevant privacy standards to uphold ethical research principles and maintain the integrity of user data throughout the project.
Data Pipeline
The data pipeline is designed to process large JSON files into a structured schema and we employed Apache Airflow
- MLflow to modularize our data pipeline.
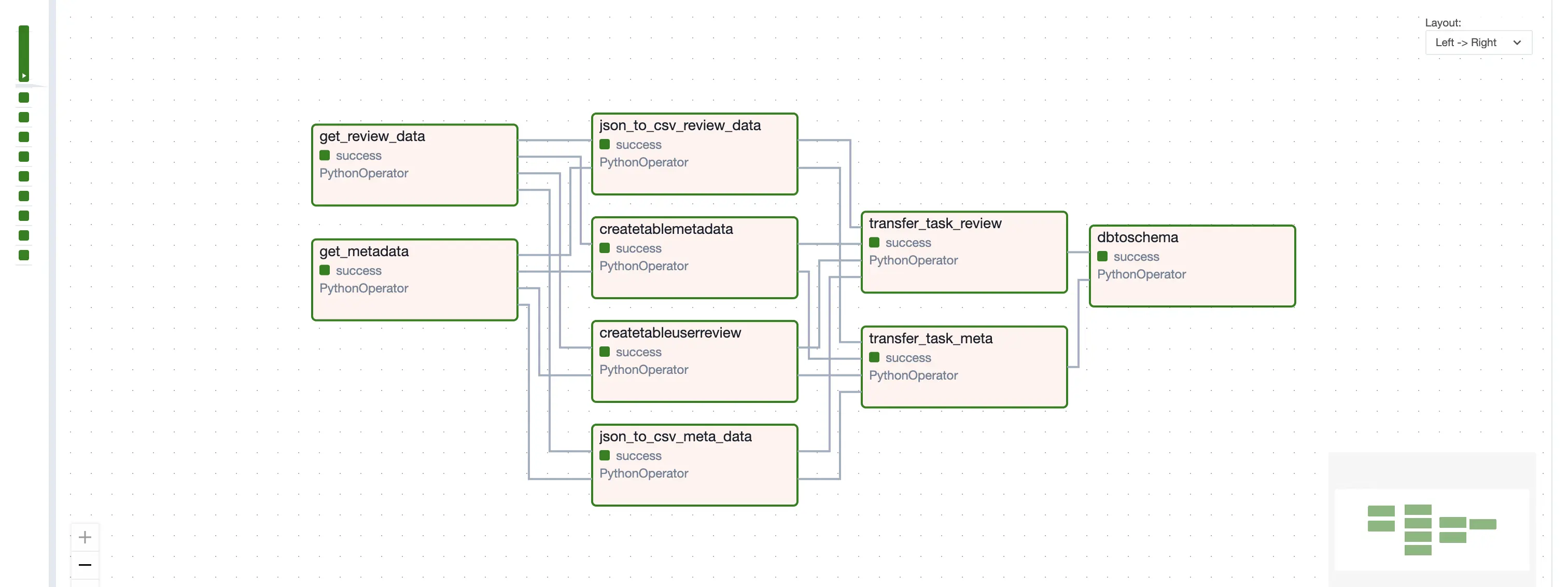
DAG Workflow
Task 1: Download Data (download_data.py)
- Operator: PythonOperator
- Description: Executes the script to:
- Download data from the specified URL.
- Extract its contents.
- Upload the extracted file to the GCS bucket.
Task 2: Establish GCS Connection (bucket_connection.py)
- Operator: PythonOperator
- Description: Configures the GCS connection using environment variables to ensure subsequent tasks can interact with the bucket securely.
Task 3: Convert JSON to CSV (json_to_csv.py)
- Operator: PythonOperator
- Description: Runs the script to:
- Download JSON data from the GCS bucket.
- Transform the JSON data into CSV format using Pandas.
- Upload the processed CSV file back to the GCS bucket.
Task 4: Establish Database Connection (db_connection.py)
- Operator: PythonOperator
- Description: Configures the database connection to Google Cloud SQL using secure credentials.
Task 5: Load CSV into Database (CSV_to_DB.py)
- Operator: BashOperator
- Description: Executes the Google Cloud CLI commands to:
- Create the user review and metadata tables.
- Import the CSV data from the GCS bucket into the PostgreSQL tables.
Task 6: Clean and Structure Database (db_to_schema.py)
- Operator: PythonOperator
- Description: Cleans and restructures the database by:
- Removing invalid image URLs from the metadata table.
- Splitting the metadata and review tables into four smaller, purpose-specific tables.
The setup and scripts to run the data pipeline can be found here: GitHub - Data Pipeline